Adaptive and supervised sparse representation based approach for noisy speech analysis
Vijay Girish and A G Ramakrishnan
Introduction
Different aspects of machine listening are addressed using two different approaches, namely
- A supervised and adaptive sparse representation based approach for identifying the type of background noise and the speaker and separating the speech and background noise
- An unsupervised acoustic-phonetics knowledge based approach for detecting transitions between broad phonetic classes in a speech signal and significant excitation instants called as glottal closure instants (GCIs) in voiced speech, for applications like speech segmentation, recognition and modification
Machine Listening
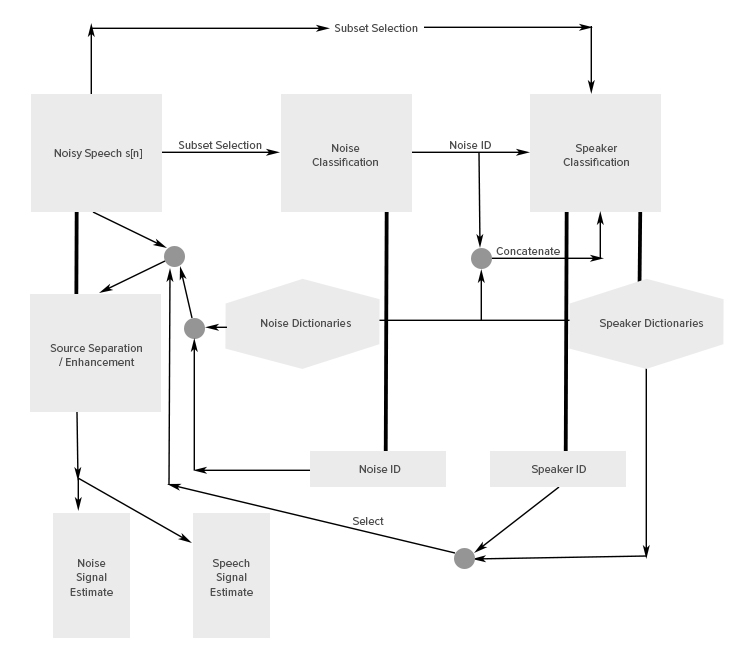
Machine Listening System Pipeline
Real life speech signals generally contain a foreground speech by a particular speaker in the presence of a background environment like factory or traffic noise. These audio signals termed as noisy speech signals are available in the form of recordings say, audio intercepts or real time signals which can be single channel or multi channel. Real time signals are available during mobile communication and in hearing aids. Processing of these signals has been approached by the research community for various independent applications like classification of components of the noisy speech signal, source separation, enhancement, speech recognition, audio coding, duration modification and speaker normalization.
Machine listening encapsulates solutions to these applications in a single system. It extracts useful information from noisy speech signals, and attempts to understand the content as much as humans do. In the case of speech enhancement, especially for the hearing impaired, the suppression of background noise for improving the intelligibility of speech would be more effective, if the type of background noise can be classified first. Other interesting applications of noise identification are forensics, machinery noise diagnostics, robotic navigation systems and acoustic signature classification of aircrafts or vehicles. Another motivation to identify the nature of background noise is to narrow down to the possible geographical location of a speaker. Speaker classification helps us to identify the speaker in an audio intercept.