Class-specific Speech Enhancement Approaches for Phoneme Recognition
Nazreen P M and A G Ramakrishnan
In the past decade, there has been tremendous improvements in the field of automatic speech recognition (ASR). Despite these, the performance of an ASR system degrades significantly in the presence of noise due to the mismatch be- tween the training and test environments, for example, when training is done on clean speech and testing is performed on noisy speech. The presence of noise distorts the spectrum of speech and hence degrades the performance.
Several techniques have been proposed to address this problem, and improve the recognition performance in noisy environments. One approach is to enhance the speech as a front end processing before it is fed into the recognizer, thereby obviating the need to retrain the ASR system for different noise statistics. The goal of my research is to find novel speech enhancement approaches to improve the phoneme recognition performance of ASR.
A class-specific speech enhancement for phoneme recognition: a dictionary learning approach
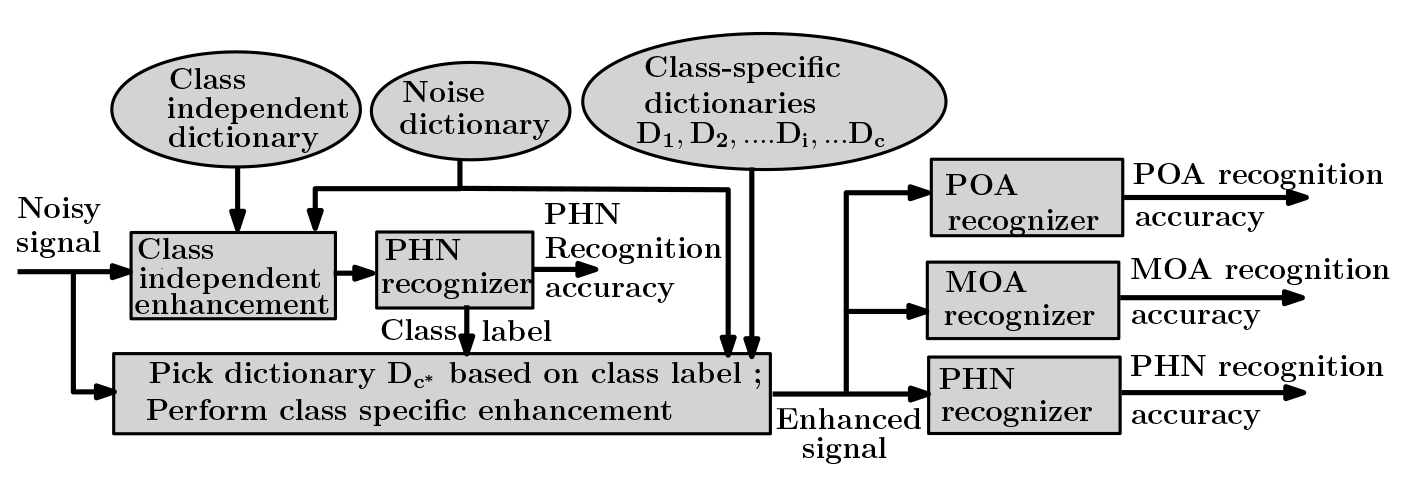
Phoneme recognition on speech enhanced with class specific dictionaries
In this work we study the influence of using class-specific dictionaries for en- hancement over class-independent dictionary in phoneme recognition of noisy speech. We hypothesize that, using class-specific dictionaries would remove the noise more compared to a class-independent dictionary, thereby resulting in better phoneme recognition. Experiments are performed with speech data from TIMIT corpus and noise samples from NOISEX-92 database. Using KSVD, four types of dictionaries have been learned: class-independent, manner-of- articulation-class (MOA), place-of-articulation-class (POA) and 39 phoneme- class (PHN). Initially, a set of labels are obtained by recognizing the speech, enhanced using a class-independent dictionary. Using these approximate labels, the corresponding class-specific dictionaries are used to enhance each frame of the original noisy speech, and this enhanced speech is then recognized.